由于工作变动,停更了很久,现在安定下后,总结下iOS多线程安全的思考。
为什么要用多线程
多线程,作为实现软件并发执行的一个重要的方法,它能够在时间片里被CPU快速切换,来提高cup资源利用率,但多线程常常伴有资源抢夺的问题,作为一个高级开发人员并发编程那是必须要的,同时解决线程安全也成了我们必须要要掌握的基础。
多线程安全
当我们在讨论多线程安全的时候,具体讨论的是什么?
当我们讨论多线程安全的时候,其实是在讨论多个线程同时访问一个内存区域(非数值类型及指针类型)的安全问题。
为什么多线程访问一个内存区域就不安全了?
我们可以看一个简单例子,从汇编角度的看下这个问题。首先我们要知道,CPU不能直接从内存中读取数据,会先将内存中的数据存储到通用寄存器中,然后再对通用寄存器中的数据进行运算.
1 | int count = 0; |
我们可以看到完成一次count++并不是简单的一步完成,而是三步:
取出count存放到临时寄存器上
对寄存器的值+1
将计算后的值存放回count的内存
在三步未完成前,多线程如果操作了count,都可能造成数据损坏。
下面我主要从以下两方面阐述多线程安全:
一,线程同步安全方案
本质是不让多个线程同时访问同一个资源,只要按顺序访问资源
1.iOS中的锁
- 自旋锁和互斥锁
自旋锁等待的时候,会忙等,消耗CPU。
互斥锁等待的时候,会休眠,不消耗CPU。
(互斥锁申请加锁时会使得线程阻塞,阻塞的过程又分两个阶段,第一阶段是会先空转,可以理解成跑一个while循环,不断地去申请锁,在空转一定时间之后,线程会进入waiting休眠状态,此时线程就不占用CPU资源了)
为什么会有这两个阶段呢?
如果单纯在申请锁失败之后,立刻将线程状态挂起,会带来context切换的开销
如果单纯在申请锁失败之后,不断轮询申请加锁,很久很久才能可用,浪费了宝贵的CPU时间
自旋锁:
OSSpinLock
自旋锁,目前已经不再安全,可能会出现优先级反转问题。
如果等待锁的线程优先级较高,它会一直占用着CPU资源,优先级低的线程就无法释放锁互斥锁:
os_unfair_lock
os_unfair_lock用于取代不安全的OSSpinLock
pthread_mutex(普通锁,递归锁,或者条件锁)
NSLock
对pthread_mutex普通互斥锁进行了面向对象的封装。@synchronized
结构在工作时为传入的对象分配了一个递归锁。它需要使用一个唯一的标识用来区分保护锁.
优点:使用起来十分简单不需要在代码中显式的创建锁对象,便可以实现锁的机制,并且不用担心忘记解锁的情况出现。同时synchronized不需要像NSLock一样需要考虑在加解锁时需要在同一线程中的问题,也不需要考虑同一个线程中连续加锁的问题。
缺点:性能较差,一般用在多线程情况下访问属性的情况NSRecursiveLock
对mutex递归锁的封装,在被同一线程重复获取时不会产生死锁。它会记录上锁和解锁的次数,当二者平衡的时候,才会释放锁,其它线程才可以上锁成功
dispatch_semaphore
dispatch_queue(DISPATCH_QUEUE_SERIAL)
GCD的串行队列,也是可以实现线程同步的
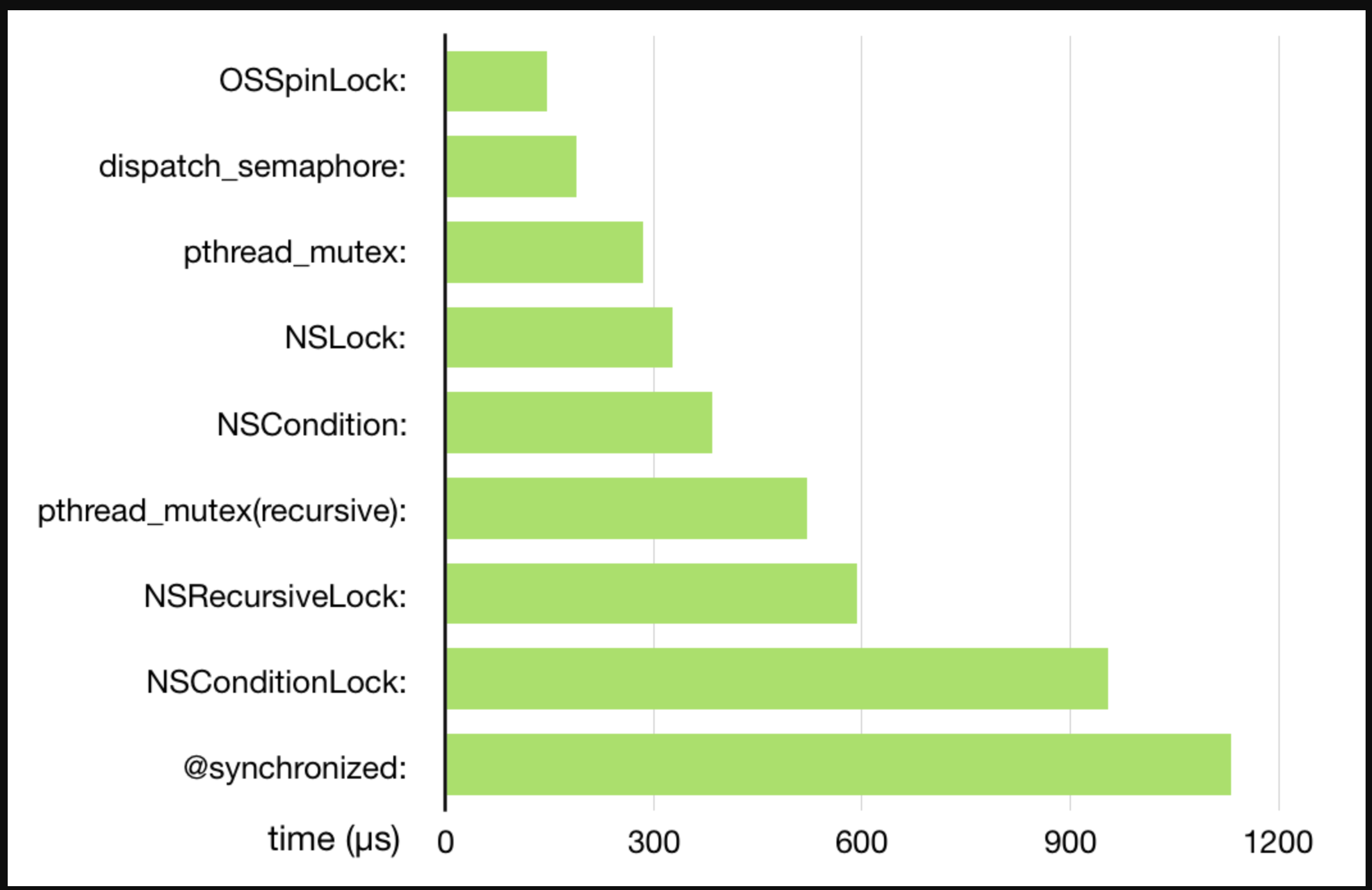
下面我看下同步方案性能从高到低排序:
死锁问题:
设置关于attr,避免死锁
1 | void thread_function() |
上面的代码看着很正常是吧?但由于在调用foo之前,mutex已经被锁住了,于是foo就停在那边等待thread_function释放mutex。但是!thread_function必须要等foo跑完才能解锁,然后现在foo被卡住了。。。
如果type设置为PTHREAD_MUTEX_ERRORCHECK,那在foo里面的pthread_mutex_lock就会返回EDEADLK。如果你要求执行foo的时候一定要处于mutex的临界区,那就要这么判断。
1 | pthread_mutexattr_t attr; |
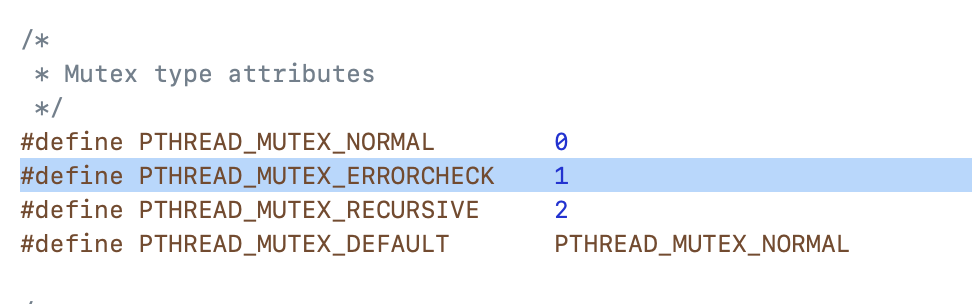
- PTHREAD_MUTEX_NORMAL,这是缺省值,也就是普通锁不提供死锁检测。当一个线程加锁以后,其余请求锁的线程将形成一个等待队列,并在解锁后按优先级获得锁。这种锁策略保证了资源分配的公平性。
- PTHREAD_MUTEX_RECURSIVE,嵌套锁(递归),允许同一个线程对同一个锁成功获得多次,并通过多次unlock解锁。如果是不同线程请求,则在加锁线程解锁时重新竞争。
- PTHREAD_MUTEX_ERRORCHECK,检错锁,如果同一个线程请求同一个锁,则返回EDEADLK,否则与PTHREAD_MUTEX_NORMAL类型动作相同。这样就保证当不允许多次加锁时不会出现最简单情况下的死锁。
2.atomic属性
atomic用于保证属性setter、getter的原子性操作,相当于在getter和setter内部加了线程同步的锁(使用了自旋锁,iOS 10以后,底层换成了os_unfair_lock)。
atomic是线程安全的吗?
这样说是片面的不准确的。
首先我们要了解:
64位系统的地址总线对于读写指令可以支持8个字节的长度,所以对于BOOL的读和写操作我们可以认为是原子的,所以当我们声明BOOL类型的property的时候,从原子性的角度看,使用atomic和nonatomic并没有实际上的区别
如果读写(load or store)的内存长度小于等于地址总线的长度,那么读写的操作是原子的,一次完成。比如bool,int,long在64位系统下的单次读写都是原子操作。
很多文章谈到atomic和nonatomic的区别时,都说atomic是线程安全,其实这个说法是不准确的.
atomic属性保证的属性的值修改(包括数值类型及指针类型)线程安全,但不保证指针指向的内存的安全及多部操作的原子性
atomic只是对属性的getter/setter方法进行了加锁操作,这种安全仅仅是set/get的读写安全,并非真正意义上的线程安全,因为线程安全还有读写之外的其他操作(比如:如果当一个线程正在get或set时,又有另一个线程同时在进行release操作,可能会直接crash,又比如一个属性array,atomic的话只能保证在外面set和get的时候线程安全,但是不能保证array addObject、removeObject线程安全)
简而言之,atomic的作用只是给getter和setter加了个锁,atomic只能保证代码进入getter或者setter函数内部时是安全的,一旦出了getter和setter,多线程安全只能靠程序员自己保障了
锁的粒度
同时我们还需要注意锁定粒度,粒度过大,造成不必要的性能损失,粒度过小,锁失效。
二,资源读写安全方案
本质就是多读单写,单位时间内读写操作只允许存在一种。
读写锁 (共享锁)-> pthread_rwlock
- 当读写锁被一个线程以读模式占用的时候,写操作的其他线程会被阻塞,读操作的其他线程还可以继续进行。
- 当读写锁被一个线程以写模式占用的时候,写操作的其他线程会被阻塞,读操作的其他线程也被阻塞。
异步栅栏调用 -> dispatch_barrier_async
这个函数传入的必须是自己通过dispatch_queue_cretate创建的DISPATCH_QUEUE_CONCURRENT并发队列,如果传入的是一个
串行或是一个全局的并发队列,那这个函数便等同于dispatch_async函数的效果
避免写线程饥饿:
读写锁必须要等到所有读锁都释放之后,才能成功申请写锁,只要有读锁在,写锁就无法申请,然而读锁可以一直申请成功,就导致所谓的插队现象。
那么写线程就不知道什么时候才能申请成功写锁了,然后它就饿死了。
为了控制写线程饥饿,必须要在创建读写锁的时候设置属性PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE,默认是PTHREAD_RWLOCK_PREFER_READER_NP。
总的来说,这样的锁建立之后一定要设置优先级,不然就容易出现写线程饥饿。而且读写锁适合读多写少的情况,如果读、写一样多,那这时候还是用mutex锁比较合理。
接口简洁但是却不友好,需要注意pthread_rwlock_t是值类型,用=赋值会直接拷贝,不小心就会浪费内存,另外用完后还需要记得销毁,容易出错,有没有更高级更易用的API呢?
异步栅栏调用 -> dispatch_barrier_async(GCD的barrier属于写者优先的实现)
这个函数传入的必须是自己通过dispatch_queue_cretate创建的DISPATCH_QUEUE_CONCURRENT并发队列,如果传入的是一个串行或是一个全局的并发队列,那这个函数便等同于dispatch_async函数的效果
1 | dispatch_queue_t queue = dispatch_queue_create("top.istones.rwQueue", DISPATCH_QUEUE_CONCURRENT); |
使用GCD还有个潜在优势:GCD面向队列而非线程,dispatch至某一队列的任务,可能在任一线程上执行,这些对开发者是透明的,这样设计的好处显而易见,GCD可以根据实际情况从自己管理的线程池中挑选出开销最小的线程来执行任务,最大程度减小context切换次数。